특집: 초거대 AI의 미래(1)
챗GPT에게 묻는 한국의 미래
인간처럼 사고하는 ‘인공지능’은 수 십년 동안 SF 영화에서나 등장하는 상상의 이야기였다. 그러나 최근 소개되고 있는 챗GPT와 ‘DALL-E2’ 같은 생성형 인공지능은 그동안 인간의 고유 영역이었던 지적노동 역시 자동화되고 대량생산 될 수 있는 가능성을 보여주고 있다. 기계가 글을 쓰고, 그림을 그리고, 새로운 지식을 창출해낼 수 있는 미래가 멀지 않아 보이는 오늘날 우리는 질문해야 한다. 지구에서 인간이 더 이상 가장 똑똑한 존재가 아닌 미래시대에 인간의 가치와 역할은 과연 무엇일까?

<그림 1> 생성형 AI (DALLE-2) 사용해 만든 인간과 미래형 안드로이드의 대화
대한민국에서 인공지능 시대를 맞이하며
인공지능(AI) 시대가 도래함에 따라 전 세계는 새로운 기술적 혁신을 경험하고 있다. 대한민국 역시 이러한 변화의 중심에 서 있으며, 우리는 이 변화를 포용하고 이를 발전의 원동력으로 삼아야 한다. 인공지능의 발전은 단순한 기술적 혁신이 아닌, 사회 전반에 걸친 긍정적 변화를 가져올 수 있다. 하지만 동시에 AI의 부정적인 영향도 함께 고려해야 한다.
우선, 인공지능은 대한민국 경제에 새로운 동력을 가져올 것으로 전망된다. 자동화와 최적화를 통해 생산성과 효율성이 향상되면서, 기업들이 더 나은 제품과 서비스를 제공할 수 있게 된다. 더불어 AI 기술의 도입은 의료, 교육, 보안 등 다양한 산업에 혁신적 변화를 가져올 것으로 기대된다. 이러한 변화는 국민들의 삶의 질을 높이고, 대한민국이 세계에서 경쟁력 있는 나라로 발전하는 데 기여할 것이다.
그러나, 인공지능 시대가 가져올 수 있는 부정적인 측면도 무시할 수 없다. AI 기술의 발전에 따른 일자리 감소와 같은 사회적 문제는 불안정과 불평등을 증가시킬 수 있다. 이로 인해 사회 구조가 더욱 복잡해질 것이며, 국가 차원에서 대응책을 마련해야 할 것이다. 또한 데이터 프라이버시(Data Privacy)와 보안, 그리고 인공지능의 부적절한 활용으로 인한 윤리적 문제도 큰 관심을 기울여야 할 분야이다.
이러한 이유로, 대한민국에서 인공지능 시대를 맞이하기 위해서는 국가 차원에서 적극적인 정책과 지원이 필요하다. 교육을 통해 미래 세대들이 AI 기술과 함께 성장할 수 있는 역량을 갖추도록 해야 하며, 기술 개발과 규제 개선을 통해 혁신 산업이 지속적으로 성장할 수 있게 해야 한다.
무엇보다, 사회 전반의 불평등과 불안을 최소화하기 위해 일자리 창출과 재교육 프로그램에 투자하는 것이 중요하다. 산업 구조의 변화에 따른 신규 일자리를 발굴하고, 기존의 일자리가 줄어드는 분야의 근로자들을 위한 전문화 교육 프로그램을 마련하여, 사회 구성원들이 인공지능 시대에 적응할 수 있도록 돕는 것이 필요하다.
또한, 데이터 프라이버시와 보안에 대한 규제와 감독을 강화함으로써 개인정보의 유출과 보안 위협을 줄일 수 있다. AI 기술의 윤리적 활용에 대한 가이드라인을 마련하고, 부적절한 활용으로 인한 사회적 불균형을 예방하는 정책을 시행해야 한다.
결국, 대한민국이 인공지능 시대를 성공적으로 맞이하려면, 긍정적 기회를 최대한 활용하고 동시에 위험을 최소화하는 방향으로 나아가야 한다. 이를 위해 정부, 기업, 학계, 그리고 시민사회가 함께 노력하고 협력하여 지속 가능한 성장과 발전을 추구해야 한다.
인공지능 시대의 대한민국은 기술적 혁신과 사회적 변화의 균형을 이루며 세계적인 선도국가로서의 위치를 더욱 공고히 해 나갈 것이다. 이러한 미래를 위해서는 우리 모두가 한 목소리로 변화를 포용하고, 도전을 이겨내는 데 앞장서야 할 것이다. 그렇게 함으로써 대한민국은 인공지능 시대를 선도하는 나라로 거듭날 수 있을 것이다.
인공지능의 짧은 역사
위의 글은 인간이 쓰지 않았다. OpenAI사의 생성형 인공지능 챗GPT에게 “인공지능 시대 대한민국의 기회와 위기”라는 주제로 글을 써 달라고 부탁한 결과다. 완벽한 문법과 문맥으로 작성된 글이다. 내용은 그다지 신선하지 않지만, 선입견 없이 읽는다면 기계가 작성한 글이라고 쉽게 결론 내리기 어려운 수준이다. 2023년은 추후 인류역사에 중요한 변곡점으로 기억될지도 모른다. 기계가 드디어 인간의 언어를 이해하고 인간과 대화가 가능한 기계가 처음 등장한 해로 말이다.
사실 인공지능의 역사는 지난 60년 동안 언제나 희망과 절망의 반복이었다. 2차 세계대전을 계기로 ‘컴퓨터’가 등장하였고, 인간이 그렇게도 어려워하는 계산을 너무나도 정확하고 빠르게 풀어주는 기계를 경험한 과학자들은 질문하기 시작했다: 인간에게 어려운 문제를 이토록 쉽게 풀 수 있다면, 인간에게 쉬운 물체인식이나 언어처리는 너무나 쉽게 해결되지 않을까? 특히 자연어처리와 자동번역은 가장 중요했다. 냉전시대였던 1950년도에는 천재적인 구소련 과학자들의 논문을 최대한 빨리 영어로 번역해야 했기 때문이다. 러시아어로 작성된 논문을 영어로 자동 번역하는 기술을 개발하는데 얼마나 걸릴까? 1950년도 인공지능 전문가들은 자신 있게 대답한다: 6개월 정도면 충분히 풀 수 있는 문제라고.
하지만 자연어처리는 60년 넘도록 풀리지 않았고, 챗GPT같은 생성형 인공지능 덕분에 이제서야 인간의 언어와 글을 이해하는 기계가 등장하기 시작했다. 도대체 뭐가 문제였을까? 초기 인공지능 시대에 사용했던 방법은 ‘기호기반’ 또는 ‘규칙기반’ 인공지능이라 부른다(symbolic AI; rule-based AI). 이 방법에 따르면 과학자와 공학자들이 수식과 코딩을 사용해 기계에게 세상을 하나하나 설명해 주어야 한다. “고양이란 이런 거야”, “강아지란 이런 거야” 하는 식으로 말이다. 하지만 30년 넘게 노력해보아도 기계는 세상을 이해하지 못한다. 더구나 발달심리학 결과에 따르면 인간은 설명이 아닌 경험과 학습을 통해 대부분 지식을 습득한다고 알려져 있다. 그렇다면 기계에게도 학습능력을 부여하면 어떨까? ‘기계학습’ 위주 인공지능의 시작이었다. 하지만 1980년도 시작된 초기 기계학습 역시 실패로 끝나버린다. 영화에서는 그렇게 많은 인공지능이 등장했지만, 현실에서의 인공지능은 60년 가까이 실패만 반복하던 분야였던 것이다.
모두가 인공지능을 포기하기 시작했다. 그런데 2012년 토론토 대학교 제프리 힌턴 (Geoffrey Hinton) 교수팀은 인간의 뇌를 모방한 ‘심층 인공신경망’ 구조를 가진 기계가 그 어느 기계보다 뛰어난 물체인식 성능을 보여준다는 결과를 소개한다. ‘심층학습(Deep Learning)’이라 불리는 이 기술적 혁신 덕분에 지난 10년 동안 기계가 세상을 알아보기 시작했고, 우리는 이제 더 이상 인간만이 아닌 기계 역시 사물을 구별하고 얼굴을 알아보는 ‘인식형 인공지능’ 시대에 살기 시작한 것이다.
그렇다면 이제 궁금해진다. 60년 동안 실패하던 인공지능 기술이 왜 갑자기 성공하기 시작한 걸까?
우선 1980년도 기계학습보다 더 발달된 알고리즘과 컴퓨터 기술 덕분이겠다. 하지만 심층학습의 진정한 성공비결은 ‘빅데이터(Big Data)’였다. 1990년도 중반부터 보편화된 인터넷 덕분에 이제 천문학적 수준의 ‘빅데이터’가 존재하고, 고양이, 강아지 사진 10만, 100만 장을 사용하기 시작하자 드디어 기계가 세상을 알아보기 시작한다. 하지만 지난 10년 동안 데이터로도 여전히 해결되지 못한 문제가 하나 있었다. 바로 자연어 처리였다. 애플 시리, 아마존 엘렉사, 마이크로소프트 코타나, 그리고 국내 통신사의 ‘AI 스피커’들에겐 공통점이 하나 있다. 바로 말귀를 너무나도 못 알아듣는 점이다. 세상을 알아보는 인공지능은 가능한데, 왜 글과 언어를 이해하는 AI는 불가능한 걸까? 바로 언어에는 순서가 있다는 차이점 때문이다. 단어와 단어사이 순서가 전체 문장의 의미를 바꾸어 놓을 수 있고, 문장이 길어질수록 그 전 단어들까지 모두 기억하고 학습해야 한다는 점 때문에 인공지능의 자연어 처리에는 본질적인 한계가 있다. 그런데 2017년 구글 사 연구원들은 매우 긴 문장 역시 학습 가능한 ‘트랜스포머(Transformer)’ 알고리즘을 개발하는데 성공한다. 수 천억 개가 넘는 초거대 스케일 데이터에 트랜스포머 인공지능 알고리즘을 적용하면 ‘거대 언어모델(Large Language Model, LLM)’ 을 구현할 수 있다. 마치 언어와 문장의 ‘확률적 지도’ 같은 역할을 하는 LLM은 이제 입력된 문장에 확률적으로 가장 잘 어울리는 단어와 문장을 만들어 낼 수 있게 된다.
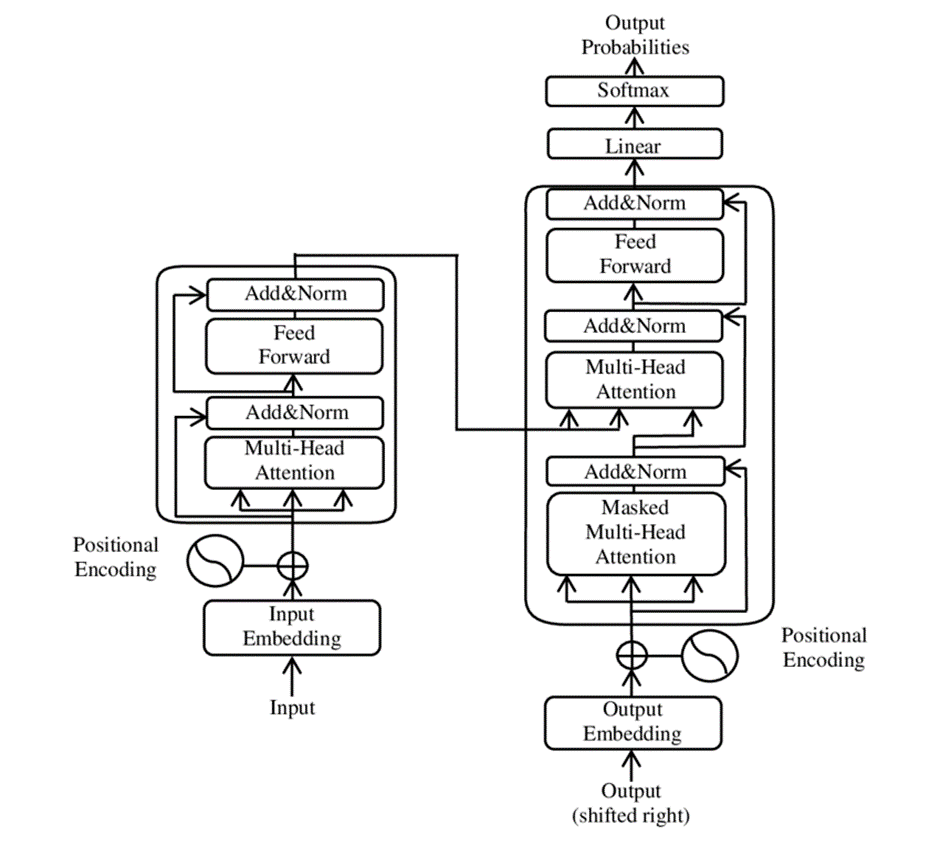
<그림 2> 2017년 구글이 개발한 트랜스포머 구조
출처: Wikipedia
트랜스포머 알고리즘은 구글이 개발했지만, 가장 발빠르게 상용화 한 곳은 ‘OpenAI’라는 스타트업이었다. 2022년 4월 공개된 DALL-E2는 입력된 문장과 가장 잘 어울리는 그림을 그려주고, 2022년 11월 소개된 챗GPT와는 의미 있는 대화가 가능하다. 세상에 이미 있는 것을 구별하고 알아보는 ‘인식형 인공지능’을 뛰어넘는 ‘생성형 인공지능’ 시대가 이제 막 시작된 것이다.
생성형 인공지능과 인류의 미래
기계가 그림을 그리고 글을 쓰기 시작한 시대. 생성형 AI가 그린 그림과 작성한 글은 대부분 인간의 창작물과 구별하기 어렵다. 그런 의미에선 생성형 인공지능은 이미 ‘튜링 테스트’를 통과한 것이다! 기계가 인간 고유의 지적노동을 대량생산하기 시작한다면 앞으로 인류는 어떤 일을 할 수 있을까? AI 시대의 사회, 정치, 경제, 그리고 국제관계와 전쟁은 어떤 변화를 경험하게 될까? 챗GPT 같은 생성형 인공지능 덕분에 무한의 가짜뉴스가 만들어질 수 있는 미래에는 어쩌면 대부분 ‘참’과 ‘거짓’의 차이를 느끼지도, 관심을 가지지도 않는 세상이 될 수도 있겠다.
하지만 생성형 인공지능의 진정한 의미는 ‘지구의 주인’이 더 이상 우리 호모 사피엔스가 아닌, 인간의 지능과 능력을 뛰어넘는 다른 존재가 될 수 있는 미래가 더 이상 불가능해 보이지 않는다는 사실이겠다. 우리는 여전히 챗GPT 같은 거대언어모델이 정확하게 어떻게 적절한 문장을 만들어 내는지 이해하지 못한다. 더구나 LLM 모델 크기가 늘어날수록, 아무도 기대하지 못했던 새로운 능력이 추가된다는 놀라운 경험을 하고 있다. 문법을 배우지 않은 챗GPT는 문법적으로 옳은 문장을 만들어내고, 수학과 논리를 가르쳐 준 적이 없는데, 논리적 사고를 한다. 그렇다면 챗GPT보다 10배, 100배, 100만배 더 큰 언어모델들은 어떤 새로운 능력을 가지게 될까? 가르쳐주지 않은 걸 추론해내고, 한 특정 영역만이 아닌, 언어로 표현 가능한 모든 분야의 문제를 풀기 시작한 생성형 인공지능은 어쩌면 ‘강한 인공지능’의 첫 단계인 AGI (Artificial General Intelligence), 그러니까 범용적 인공지능으로 지금 이 순간 진화하고 있는지도 모르겠다. 범용적 인공지능과 강한 인공지능의 첫 단계일지도 모르는 생성형 인공지능의 등장은 단순히 미래 일자리와 산업구조를 넘어, 인류 전체의 미래에 대한 진지한 걱정과 고민의 계기가 되어야 하겠다.
* 이 글의 내용은 아시아연구소나 서울대의 견해와 다를 수 있습니다.

Tag:챗GPT,한국의미래,OpenAI,생성형AI,인공지능
이 글과 관련된 최신 자료
- Gates, Bill (2023). “The Age of AI has begun.” Gatenotes.
https://www.gatesnotes.com/
- Chomsky, Noam (2023). “The false promise of Chat GPT.” The New York Times.
https://www.nytimes.com/
- Henry Kissinger, Eric Schmidt, and Daniel Huttenlocher (2021), The Age of AI: And Our Human Future, Little: Brown and Company.
저자소개
김대식 (daeshik@kaist.ac.kr)
현) 카이스트 전기 및 전자공학부 교수
전) Boston University 부교수, University of Minnesota 조교수
주요 저서: 『챗GPT에게 묻는 인류의 미래』 (동아시아, 2023)
『메타버스 사피엔스』 (동아시아, 2022)
『초가속』 (공저) (동아시아, 2022)